(JS) 進化計算における遺伝子的アルゴリズムでbitを用いて子を生成する方法の速度検証
やったこと
遺伝子的進化計算において、親から子を作成する(交叉する)ときに2つのやり方のうちどちらが早いのかを計算した備忘録。
具体的に、遺伝子長列(NUM_OF_GENE)に対して親が2体(NUM_OF_PARENT)、子を30対(NUM_OF_CHILD)作るときに、親の遺伝子から30種類の子の遺伝子を作る。このときに30+2 = 25なので、5-1個の交叉位置を用いる。 このときに、bit配列を生成せずに書くか、bit配列を生成して書くかの速さについて検証する。なお以下にコードを示すが、bit配列を用いる方がシンプルである。
前提
const NUM_OF_PARENT = 2; // 親の数 const NUM_OF_CHILD = 32; // 子の数(30+2であり、2は親と同じものが生成される) const NUM_OF_GENE = 1000; // 遺伝子の長さ const N =10; // 計測用の繰り返し回数(10,100,1000で検証する) const NUM_OF_SEPARATOR = Math.log(NUM_OF_CHILD) / Math.log(2)-1; // 交叉位置の数、log2(NUM_OF_CHILD)-1 const LENGTH_OF_BITBOX = Math.log(NUM_OF_CHILD) / Math.log(2); // 何桁のbit配列を必要とするのか //--親の生成--// var parent = new Array(NUM_OF_PARENT); for(var i=0;i<NUM_OF_PARENT ;i++){ parent[i] = new Array(NUM_OF_GENE); for(var j=0;j<NUM_OF_GENE ;j++){ parent[i][j] = i; } } //--生成された親の確認--// console.log(parent[0]); // 全て0の遺伝子 console.log(parent[1]); // 全て1の遺伝子 //--子の遺伝子を入れる配列の生成--// var child = new Array(NUM_OF_CHILD); for(var i=0;i<NUM_OF_CHILD ;i++){ child[i] = new Array(NUM_OF_GENE); } //--交叉位置の設定--// var rand = new Array(NUM_OF_SEPARATOR); for(var i=0;i<NUM_OF_SEPARATOR;i++){ //--重複のない乱数を生成する--// while(true){ tmp = Math.floor(Math.random()*NUM_OF_GENE); if(!rand.includes(tmp)){ rand[i] = tmp; break; } } } rand.sort(); // 交叉位置を昇順に console.log(rand); // 交叉位置の確認
パターン1(bit配列を生成しない)
const startTime1 = performance.now(); // 開始時間 for(var i=0;i<N;i++){ pattern1(); // 計測する処理 } const endTime1 = performance.now(); // 終了時間 console.log("パターン1の計測時間::"+(endTime1 - startTime1)); // 何ミリ秒かかったかを表示する function pattern1(){ var rand_position =0; // 交差位置を入れる var choiced_parent =0; // どちらの親を選択しているのか var count=0; // どの点で親を交代するのか //--遺伝子1つ1つに対してのループ--// for(var c=0;c<NUM_OF_GENE;c++){ // 交差位置を変更する if(c>=rand[rand_position]){ rand_position++; } // どの子供の遺伝子を親を同じにするのか for(var i=0;i<NUM_OF_CHILD;i++){ child[i][c] = parent[choiced_parent][c]; count++; // 親と同じにした子の数を取得(どこで親を切り替えるのか) // 交差位置においてどのタイミングで親を切り替えるのかを選択する。 // 初め(30この親を生成する場合)は16個の子が親0と同じで残りの16個の子が親1と同じであるが、交差位置が最後になるとiが変わるループ内で交互に親が入れ替わる。bit配列を書くとわかりやすい。 if(count>=2**(NUM_OF_SEPARATOR-rand_position)){ count=0; choiced_parent = choiced_parent ^ 1; } } } }
パターン1(bit配列を生成する。)
const startTime2 = performance.now(); // 開始時間 //--bit配列の生成--// var bitBox = []; for(let i = 0; i < (1 << LENGTH_OF_BITBOX); i++){ bitBox.push(i.toString(2).padStart(LENGTH_OF_BITBOX, '0')); } for(var i=0;i<N;i++){ pattern2(); // 計測する処理 } const endTime2 = performance.now(); // 終了時間 console.log("パターン2の計測時間::"+(endTime2 - startTime2)); // 何ミリ秒かかったかを表示する function pattern2(){ var rand_position =0; //--遺伝子1つ1つに対してのループ--// for(var c=0;c<NUM_OF_GENE;c++){ // 交差位置を変更する if(c>=rand[rand_position]){ rand_position++; } // 各bitが0,1によって親を変える。 for(var i=0;i<NUM_OF_CHILD;i++){ child[i][c] = parent[bitBox[i][rand_position]][c] } } }
bitについての補足


結果
# N=10 パターン1の計測時間::9.599999994039536 パターン2の計測時間::6.0999999940395355 # N = 100 パターン1の計測時間::33.900000005960464 パターン2の計測時間::35.400000005960464 # N = 1000 パターン1の計測時間::250.59999999403954 パターン2の計測時間::328.59999999403954
Nが大きくなるとbit配列の方が大きくなる。bit配列を用いる方は配列の番地を指定する際に配列を用いているため処理速度の低下が伺える。
参照回数が多いときにはパターン1が有効であり、コードの短さが必ずしも早いとは限らない。
(Python)tkcalendarで土日を青、赤に変える
やったこと

最初に
tkcalendarを使っていて、土日の色を青と赤の別の色に変えようとしたけど簡単にできないかったので、元のコードを変えてやったお話です。
https://tkcalendar.readthedocs.io/en/stable/Calendar.html
公式のやつをみると以下のようにすると色を変更できるよって書いてあります。
# background color of week-end days # 訳: 週末の背景の色を変えるよ〜 weekendbackground :str # foreground color of week-end days # 訳: 週末の文字の色を変えるよ〜 weekendforeground :str
ふむふむ
で結果がこれ。。。

あ、そっちね。。
土曜日は青で日曜日は赤にしたいんだ!!
確かに両方週末だけど、、
一応この時のコードです。
import tkinter as tk from tkinter import ttk from tkcalendar import Calendar, DateEntry # メインウィンドウ生成 root = tk.Tk() root.title('Calender') root.geometry('400x300') # スタイルの設定 style = ttk.Style() style.theme_use('default') style.configure('style',background='white') # カレンダーの設定 cal = Calendar(root, # 表示するウィンドウ weekendbackground="blue", # 週末の背景色 showweeknumbers=False, # 先頭に週番号をつけない style='style' # styleの指定 ) # 表示 cal.place(x=0, y=0) root.mainloop()
改善
使える関数調べてみたけどいいのなさそうだったので、もう直接変えに行きましょう。
先に結果を見せるとこんな感じ

<<手順>>
ダウンロードしたtkcalendarを自分の作業環境に持ってくる(元のファイルを直接編集してもOK)
内容を変更する。
1 ダウンロードしたtkcalendarを自分の作業環境に持ってくる
※ 元のファイルを直接編集する人は飛ばしてください。 ※ また、tkcalendarがどこにあるのかわかっている人も飛ばしてください。
まずどこにあるのかを知る
import sys print('\n'.join(sys.path))
このコマンドを使うとimportする際にどのディレクトリからimportしているのかわかるので表示されたディレクトリのどこかに"tkcalendar"が存在しているのでそれを作業しているディレクトリに持ってくる。
今回はhelperディレクトリを作成してその中に入れています。
|--- main
|--- test.py
|--- helper
|--- tkcalendar ## ここに持ってきてます
|--- __pycache__.py
|--- __init__.py
|--- __main__.py
|--- calender_.py
|--- deteentry.py
|--- tooltip.py
2 内容を変更する。
※ import先を変更します。test.py(元のコードの)
- from tkcalendar import Calendar, DateEntry + from helper.tkcalendar import Calendar, DateEntry # どこに入れたのかでhelperでない可能性あり
※ 以下の編集するファイルは全てcakendar_.pyです。
# 約400行 # __init__関数内 の self._properties=[:,:,:]に追加する。 'weekendbackground': 'blue', ### 土曜日の背景色 'weekendforeground': 'white',### 土曜日の文字色 'weekendbackground_2': 'red',### 日曜日の背景色 'weekendforeground_2': 'white',### 日曜日の文字色
# 約779行 # _setup_style関数内 の # bwe_bg = self._properties.get('weekendbackground') # we_fg = self._properties.get('weekendforeground') # この下に追加する we2_bg = self._properties.get('weekendbackground_2') ### 日曜日の色をセットする we2_fg = self._properties.get('weekendforeground_2') ### 日曜日の色をセットする
# 約794行 # _setup_style関数内 の # self.style.configure('we.%s.TLabel' % self._style_prefixe, background=we_bg,foreground=we_fg) # この下に追加する self.style.configure('we2.%s.TLabel' % self._style_prefixe, background=we2_bg,foreground=we2_fg) ### 色を変える
# 約926行 # _display_days_with_othermonthdays関数内 の変更 - week_days[self['weekenddays'][0] - 1] = 'we' + week_days[self['weekenddays'][1] - 1] = 'we2'
以上で写真のようになります。
(Latex)labelはどこに書けばいいの?
Latexを書いていてlabelの位置についてどこに書けばいいのか気になったので調べてみました。
どうせ最終的に見えないし、どこに書いたって同じでしょって思ったんですが、ちょっと違うようです、、
サンプルの内容

コード
\documentclass{jlreq} \begin{document} \section{1つ目のセクション} \label{1} \section{2つ目のセクション} \label{2} \subsection{2の1つ目のサブセクション} \label{3} \begin{table}[hbtp] \label{4} \caption{サンプル} \label{5} \begin{tabular}{cc} \label{6}\\ \hline ランキング& スコア\\ \hline 1& 10点\\ 2& 5点 \end{tabular} \end{table} \begin{description} \item[1つ目のセクションのラベル] \ref{1} \item[2つ目のセクションのラベル] \ref{2} \item[サブセクションのラベル] \ref{3} \item[表のラベル(begin\{table\}直下)] \ref{4} <-----おかしいぞ \item[表のラベル(caption直下)] \ref{5} \item[表のラベル(begin\{tabular\}内部)] \ref{6} \end{description} \end{document}
理由
4がおかしいという結果となり、2.1が表示されている。 この理由は、
\captionよりも上にあるということである。
図や表を使う際にタイトルを書く\captionが存在することにより、その下は図や表のlabelとなる。
2.1と表示されていたのはsebsectionの2.1であり、\begin{table}内でも\captionよりも上にあればtable内ではなく、sectionのlabelとして扱われる。 つまり、
\begin{table}[hbtp] \label{7} %<-----table内のlabelとして扱えない。 \caption{サンプル} \label{8} %<-----table内のlabelとして扱う \end{table}
まとめ
参照する番号を書いた場所の下であれば思うような参照が可能である。
ターミナルで色をつけて遊ぶ(ls コマンド)
lsコマンドで色を変えられることを知って面白いと思って遊んだ結果です。
結果
lsコマンドでは文字と背景の色を変えることができる。それを使って画面いっぱいを色とりどりにする。
こんな感じ!!

※これは一応ターミナルの画面です。
やり方
######## 変数の意味####################### # test.test どのファイルの色を設定するか # color_1 文字の色を指定する(30~37) # color_2 背景の色を指定する(40~47) ######################################## export LS_COLORS="test.test=color_1;color_2". # 色の設定 ls --color=auto # 色をつけて表示
LS_COLORSにより、どのファイルの文字の色を背景の色を変える設定をできます(Macの場合は書き方が異なります)。 各色についてはこちらの記事を参考にしてください。
サーバ環境セットアップ|lsコマンドで表示される文字カラーを変更
ls --color=auto によって設定した色を用いて表示します。
やったこと
これを用いてシェルスクリプトを組み、ランダムで表示させるようにした。
#!/bin/bash ######引数####### # $1=ファイルを作成する新しいディレクトリ名(のちに消される) # $2= 開始する数 # $3= 終了する数 ############## mkdir $1 # st=$2 en=$3 result="" for i in `seq $st $en` ## 繰り返す do rand0=$((RANDOM%26) # ランダムを生成(ファイル名用) value=$((RANDOM%8)) # ランダムを生成(文字用) value_2=$((RANDOM%8)) # ランダムを生成(背景用) touch $1/$rand0.$i # ファイルを作成する(ディレクトリ内部に) rand1=$((30+$value)) rand2=$((40+$value_2)) result+=*.$i=05\;$rand1\;$rand2: # 設定するための準備 done export LS_COLORS=$result # 設定する ls --color=auto $1 # 表示 rm -r $1 # 作成したディレクトリを消す
今回はLs_colorという名前で保存した。
Ls_color aaa 1 3000
このように実行した結果一番最初の画像のようになる。
(Python)Matplotlib ドーナツグラフの中央に文字を書く
久しぶりの投稿です。
Pythonでドーナツ型の中央に文字を書こうとしても良い記事がなかったので、備忘録です。
やりたいこと
最終的なイメージはこんな感じです。
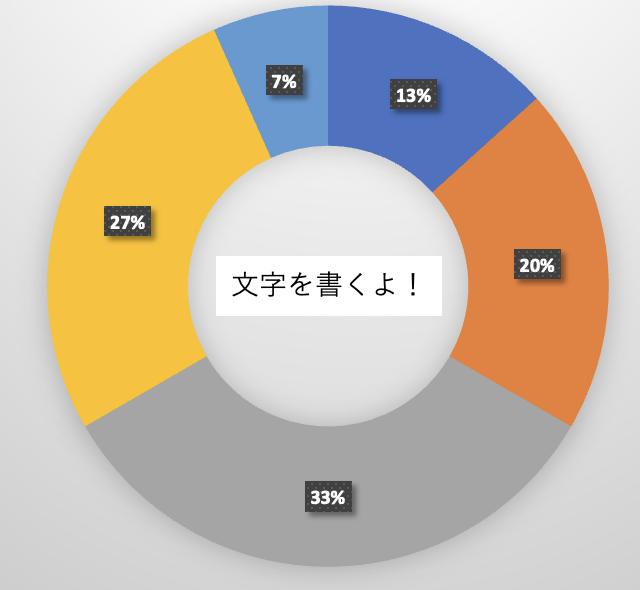
コード
import matplotlib.pyplot as plt # グラフを使えるようにする
import japanize_matplotlib # 日本語化
if __name__ == "__main__":
category = ["A","B","C","D","E"] # カテゴリー
data = [2,3,5,4,1] # 値
# 図の初期化
fig = plt.figure()
# インスタンスの生成
instance=fig.subplots()
# 文字サイズを決める
plt.rcParams['font.size'] = 15
# ドーナツグラフを書く
instance.pie(
data, # データ
wedgeprops={'width':0.6} # どれだけ中心を開けるか(0.0~1.0、大きいほど中心が開く)
)
instance.set_title('文字が書けた!!', fontsize=10,y=0.45) # 中央の文字 <-----------ココがポイント
fig.suptitle('ドーナツの中央に文字を書く', fontsize=15) # 図形のタイトル
# 表示
plt.show()
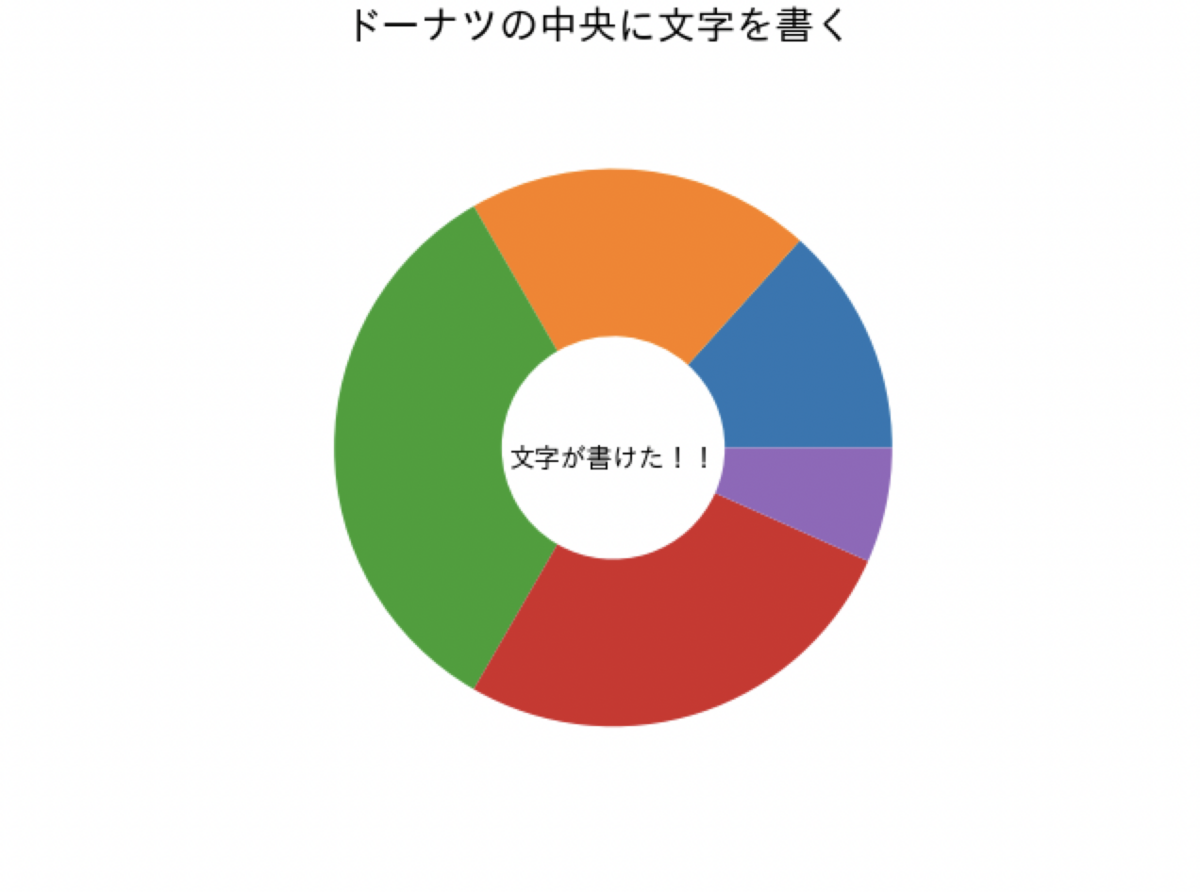
さらにプラスα
こんな要望を叶えると以下のようになります。
- 割合を大きい順に表示したい
- %表示欲しい
- 値もわかった方がいいよね(カテゴリではない)
- 色の意味も欲しい
コード(おまけ)
import matplotlib.pyplot as plt # グラフを使えるようにする import japanize_matplotlib # 日本語化 if __name__ == "__main__": category = ["A","B","C","D","E"] # カテゴリー data = [2,3,5,4,1] # 値 # 図の初期化 fig = plt.figure() # インスタンスの生成 instance=fig.subplots() # 文字サイズを決める plt.rcParams['font.size'] = 15 #---------追加---------- # 割合順に並べる zip_list = zip(data,category) data_sorted,category_sorted = zip(*sorted(zip_list,reverse=True)) # ドーナツグラフを書く instance.pie( # データ data_sorted, # 値の出力(全体の5%未満は表示しない) labels=list(map(lambda x : str(x) if x/sum(data)>=0.1 else "" ,data_sorted)), # 反時計回り counterclock=False, # 図形を90度回転 startangle=90, # %の表示(全体の5%未満は表示しない) autopct=lambda p:'{:.1f}%'.format(p) if p>=10 else '', # %の位置が中心からどれだけ離れているか(0.0~1.0、大きいほど中心が開く) pctdistance=0.7, # どれだけ中心を開けるか(0.0~1.0、大きいほど中心が開く) wedgeprops={'width':0.6} ) # 凡例を表示 instance.legend(category_sorted,fancybox=True,loc='center left',bbox_to_anchor=(1.0,0.6),fontsize=10) # ---------追加ここまで---------- # タイトル instance.set_title('やった!!', fontsize=10,y=0.45) # 中央の文字 fig.suptitle('綺麗になった!!', fontsize=15) # 図形のタイトル # 表示 plt.show()
まとめ
subplotのタイトルを使って中央に書いています。
参考
(c言語)日本語の%cによる表記
macで日本語を%cを使って躓いたことの備忘録です。。
日本語は英語とは異なり、マルチバイトを要求します。
そのため、
str[]="あいう"; printf("%c%c",str[0],str[1]);
他のサイトでよく見かける書き方。
しかし、macで実行すると、うまく表示できない。
そこでbyteを確認してみると、
int main(){ char str_1[]="あ"; char str_2[]="い"; char str_3[]="う"; printf("あ[%d],い[%d],う[%d]",sizeof(str_1),sizeof(str_2),sizeof(str_3)); return 0; }
結果
あ[4],い[4],う[4]
??? 4byte??2byteじゃないの?
てか、そしたら合計12?
int main(){ char str[]="あいう"; printf("あいう[%d]",sizeof(str)); return 0; }
結果
あいう[10]
あ、str_1,str_2,str_3の終わりに終端文字(1byte)があるんだった! つまり、ひらがなは3byte?
int main(){ char str[]="あいう"; printf("%c%c%c",str[0],str[1],str[2]); return 0; }
結果
あ
うまくいきました!
Latexの書き方と基本的な機能
初めに
Latexを書く上で基本的な部分を説明していきます。
documentclass
latexを書き始めるにあたり必要となります。
% \documentclass[オプション]{文書クラス} \documentclass[a4j,12pt][jarticle]
これは、紙の初期設定を決めます。 例のオプションでは、a4の紙に日本語で書くこと、文字の大きさは12ポイントを使うことを指定します。
文章クラスでは、この文章が何のための文章(論文、報告書、本)なのかを示すものになります。文章クラスにより使えるもの(section,chapter)が変わってくるので注意しましょう。(詳しくはこちらをクリック)
例では、日本語の論文であることを示しています。
以下に文章クラスで基本的なクラスを紹介します。
| 役割 | クラス |
|---|---|
| 論文,記事 | article |
| 報告書 | report |
| 本 | book |
ここに日本語を意味する"j"等が先頭につきます。
begin,end
beginとendはこの中で今から〇〇をしますということを宣言します。(例: 5章目を書きます、数式を書きます、図を入れますetc)
% \begin{やること} % \end{やること} \begin{section} \end{section}
例では、新しい章を始めることを意味しています。
Latexの用語的には環境といい、例のものをsection環境といいます。
document
これはここから文章を書くことを意味します。 つまりこの中に文章を書いていきます。
\begin{document} \end{document}
usepackage
usepackageではLatexのデフォルトでは入っていない機能,環境を入れていきます。
\usepackage{}は\documentclass[]{}と\begin{document}の間に書きます。
% \usepackage{入れたい機能,環境} \usepackage{url}
例では、urlの機能(簡単に書く機能)を入れています。(urlには特殊文字が多く含まれるためそれを無効化してくれます。一部無効化されませんが...)
コメントアウト
コメントアウトとはこの文章を「一回消したい!けど後で使うかもしれない」といったときに一時的に文章をないものとしてくれる便利機能です。
使い方は簡単でコメントアウトしたい行の先頭に"%"(パーセント)を付けるだけです。
実は、先ほどから度々登場しています。
数式
∫や...(ドット3つ)は検索された方が早いと思われるので割愛します。
インラインモード
インラインモードとは文中に数式を入れる形式です。もし数式を1行で表したい場合にはディスプレイモードの方を参照してください。 インラインモードにはいくつかの書き方が存在しています。
- $数式$
- (数式)
- math環境
% $数式$ $ a+b=c $
% \(数式\) \(a+b=c\)
\begin{math} %数式 a+b=c begin{math}
ディスプレイモード
ディスプレイモードとは数式の前と後で改行をして表示するやり方です。数式に番号を付けたい場合にはディスプレイモード(番号付き)を参照してください。 ディスプレイモードにはいくつかの書き方があります。
- $$数式$$
- [数式]
- displaymath環境
% $$数式$$ $$ a+b=c $$
% \[数式\] \[a+b=c\]
\begin{displaymath} %数式 a+b=c begin{displaymath}
ディスプレイモード(番号付き)
番号付きの数式にはいくつかの書き方があります。
| 種類 | 特徴 |
|---|---|
| equation | 1つだけ書けます |
| eqnarray | 複数書くことができます |
\begin{equation} % 数式 a+b=c \end{equation}
\begin{eqnarray} % 数式\\ % 数式 a+b=c\\ x*y=z \end{eqnarray}
※eqnarrayを使う際には、一番最後の行以外の行の最後の"\"を付けます。(改行を意味します。)
指定の位置で合わせる
複数の行を=等の指定の位置で揃えたい場合には"&"を使います。
\begin{eqnarray} a+b&=c\\ x*y&=z \end{eqnarray}
中央に寄せる
中央に寄せたい際にはgatherを使います。
\begin{gather} a+b=c\\ x*y=z \end{gather}
新しい書き方(align)
eqnarrayより、alignの方が新しい記述になっています。一部性能が違いますがalignの方が優れていると私は思っております。この際、\usepackage{amsmath}が必要となります。
\begin{align} a+b=c\\ x*y=z \end{align}
その他の数式について詳しい記述はこちら qiita.com
参照
参考文献
参考文献の書き方は以下のようになります。
% \cite{好きな文字} こちらは参考文献のやり方で\cite{test}。 % ---参考文献の欄------ \begin{thebibliography}{99} \bibitem{test} ,aさん『参考文献の本』,test社(2017) \end{thebibliography}
まず、\cite{}の中になにを参考にしているのかわかりやすい文字を入れましょう。
文章には表示されないため自分がわかりやすい名前にするのがよいでしょう。
\begin{thebibliography}{99}で参考文献が始まることを定義しています。99は99個以下の参考文献があることを示しています。
数式の番号の参照
数式の番号を参考にしたいときには以下の2つのやり方があります。
| 種類 | 特徴 |
|---|---|
| ref | 数字だけ表示します |
| eqrf | 数字を()でくくって表示します |
やり方
- 参照したい数式の行の一行上に\label{}を付ける
- \ref{}または\eqref{}を使って表示する
\usepackage{amsmath} \begin{align} % \label{好きな文字} \label{test1} a+b=c\\ \label{test2} x*y=z \end{align} % ---参考にしたい場所---- \ref{test1}は\eqref{tset2}を用いています。 % -----下のように表示されます。↓ % 1は(2)を用いています。
数式環境に\begin{align}を用いましたが、番号付きディスプレイモードの数式であればなんでも大丈夫です。 まず、\label{}の中になにを参考にしているのかわかりやすい文字を入れましょう。
文章には表示されないため自分がわかりやすい名前にするのがよいでしょう。
おまけ
改行後の字下げを消す
Latexでは2回改行すると強制的に字下げが入ります。しかし、字下げをしたくないときは\noindentを使います。
下が字下げされない
\noindent
字下げされてない!!
空白の行を入れる
Latexでは2回改行をしても空白の行を入れることができません。その際に\vskip\baselineskipを使います。
空白の行が欲しい!!
\vskip\baselineskip
yattaze!
意味は、\vskipをスキップしますです。つまり縦方向に空白を入れる。どのくらいを後述します。
\baselineskipは1つ分の行をという意味になるため、合わせることで一つ分の行を空けて!という意味になります。